
What Is Developer Self-Service Infrastructure and Why Startups Use It to Remove DevOps Bottlenecks
Improve developer velocity, reduce platform bottlenecks, and scale engineering efficiently.



A 15-person startup hires its first dedicated DevOps engineer. The deployment queue clears. Three months later, it’s back. They hire a second engineer. The cycle repeats.
The problem isn’t simply capacity. It’s that operational work is still centralized.
Every new service requires someone to provision infrastructure, configure permissions, set up deployment workflows, and manage environments. Whether that means creating databases, configuring IAM roles, provisioning Kubernetes resources, or wiring CI/CD pipelines, the process depends on a small number of people with specialized knowledge.
As the engineering team grows, the number of requests grows with it. The bottleneck shifts, but it doesn’t disappear.
Teams that break out of this pattern don’t just hire faster. They move to a self-service deployment workflow that allows developers to provision environments and deploy services on their own cloud accounts while operating within predefined guardrails.
TL;DR
The DevOps bottleneck is structural, not a headcount problem. Adding engineers clears the queue temporarily. The manual provisioning model stays broken.
Self-service gives developers a provisioning layer they operate directly. No ticket, no Terraform, no waiting.
Every environment gets the same template: VPC, EKS, RDS, ECR, Loki, Prometheus, Grafana. That’s how consistency is enforced across dev, staging, and production.
An internal developer platform is what implements this in practice.
What is developer self-service infrastructure?
Developer self-service infrastructure is a model where engineers provision environments, deploy services, and manage cloud resources on their own, without filing a ticket or waiting on a DevOps engineer to do it for them.
The key word is self-service, not uncontrolled. Developers work within guardrails the platform enforces. They can do what they need to ship. They cannot touch what they should not.
This is different from just giving developers cloud console access. Full AWS console access without guardrails is how production databases get accidentally deleted at 2pm on a Thursday. Self-service infrastructure means the platform handles provisioning through templates and exposes a controlled interface to developers, not a direct line to your AWS account.
What self-service infrastructure is not:
Full cloud console access — developers get IAM credentials and log into AWS directly. No guardrails, no audit trail, high blast radius.
A developer portal — a catalog UI like Backstage that organizes existing infrastructure. It does not provision or deploy anything on its own.
A PaaS like Heroku or Render — these abstract away the cloud entirely. Self-service infrastructure runs on your own AWS, GCP, or Azure account. You own the VPC, the cluster, the data. The platform manages the operational layer on top of the infrastructure you control.
Developer self-service vs DevOps-managed deployments
Speed is the obvious difference. It’s not the important one.
In a DevOps-managed setup, infrastructure knowledge lives in human memory. The senior DevOps engineer knows the production VPC uses a /16 CIDR because they designed it two years ago. They know an RDS parameter group was tweaked after a production incident and never committed back to Terraform. They know staging has a security group rule added at 11pm to unblock a deploy that never got cleaned up. None of that is documented. It lives in their head.
So when a developer needs a new environment, they need that person. Not because the task is hard. Because the knowledge required to do it safely isn’t anywhere else.
In a self-service model, that knowledge gets encoded into the provisioning template. CIDR allocation, node group sizing, parameter groups, security defaults — defined once, applied every time. A developer requesting an environment gets identical infrastructure whether it’s provisioned on a Tuesday afternoon or the night before a launch.
A few practical consequences most teams don’t anticipate:
Configuration drift mostly stops. Environments don’t drift because they’re not configured separately anymore. Staging breaks production less often because both are built from the same template.
When the engineer who set up your EKS clusters leaves, you don’t lose the ability to reproduce them. The provisioning logic is in the template, not in that person’s head.
Deployment frequency increases. Per the 2024 DORA Report, teams on self-service platforms were 1.5x more likely to be high or elite performers on deployment frequency. When developers don’t wait 3 days for an environment, they stop batching changes to justify the wait.
Why hiring more DevOps engineers doesn’t fix the deployment bottleneck
Most teams try this at least once. The queue is long, so they hire. It clears for a few months. Then it’s back.
The second hire doesn’t fix it either.
The bottleneck isn’t the person. It’s the surface area of manual work that only that person can touch:
Terraform for a new service with RDS, SQS, and IAM roles: 4 to 8 hours per service
GitHub Actions setup for a new service: 2 to 4 hours
Onboarding a new engineer with scoped AWS access and pipeline walkthrough: 1 to 2 days
A broken EKS node group mid-sprint: unpredictable, drops everything else
A second DevOps engineer splits that work between two people. Both are now context-switching between provisioning requests, broken pipelines, and on-call. The queue refills. You’re always one sprint behind.
Adding more DevOps engineers rarely fixes the underlying problem. As engineering teams grow, the volume of infrastructure requests grows as well. More developers create more services, environments, deployments, and operational work.
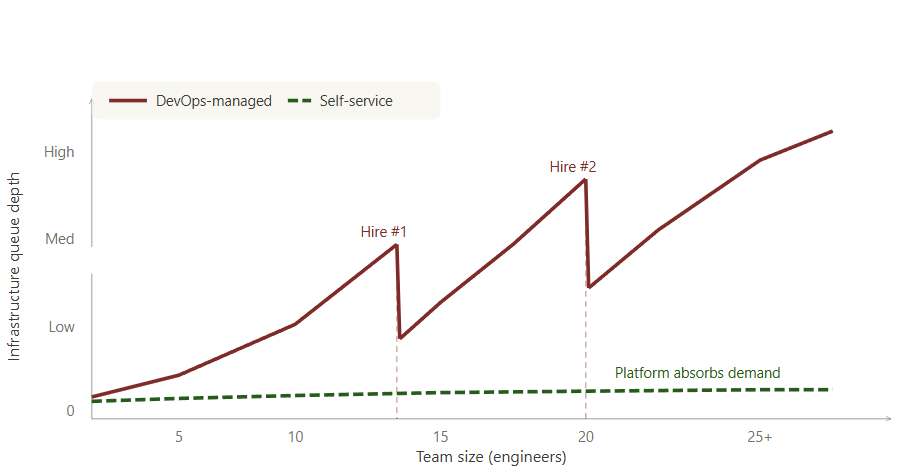
This is why ticket queues tend to reappear even after increasing headcount. The bottleneck is not the number of engineers available to handle requests. It’s the manual process behind the requests.
The 2024 DORA State of DevOps Report found that low-performing teams spend a significant portion of their time on unplanned work and rework, often driven by manual workflows, environment issues, and operational overhead.
The solution is not to scale the ticket queue. It’s to eliminate it where possible. A task that requires hours of manual provisioning should be available to developers through a self-service workflow. The goal is not to teach every developer Terraform or Kubernetes internals, but to give them a standardized platform that handles the complexity on their behalf.
The gap in a DevOps workflow without self-service: provisioning queues, environment drift, and blocked engineers
This is where the cost accumulates. Not a single failure, just a steady tax on every sprint.
Provisioning queues block delivery
A developer needs a new staging environment. DevOps is mid-incident. Ticket sits two days. Developer moves to something else. When the environment is finally ready, they need an hour to rebuild context before they can use it.
Multiply that across a 15-person team running two-week sprints. The Stack Overflow Developer Survey 2024 found that 62% of developers cite waiting on other teams or processes as their biggest productivity blocker. Infrastructure provisioning is one of the top three.
Environment drift causes production failures nobody can reproduce
This one builds slowly and quietly.
A security group rule gets added directly in the AWS console at 11pm to unblock a deploy. Never makes it back to Terraform.
An RDS max_connections parameter gets bumped in production after a connection pool exhaustion incident. Staging keeps the old value.
A Kubernetes resources.limits.memory gets adjusted during a debug session. The change never gets committed.
Three months later, a bug appears in production that staging cannot reproduce. Same application code, different infrastructure. The debugging session that follows is not an application debugging session. It is an infrastructure archaeology session. Engineers spend hours diffing configs across environments trying to find what drifted and when.
New engineers can’t ship without a DevOps handoff
Before a new engineer deploys their first service they need scoped IAM access, a working understanding of which Terraform module applies to their service type, and someone to explain why the staging pipeline config diverges from the docs. That is typically 1 to 2 days of a senior engineer’s time per hire.
A team hiring 4 engineers a year loses 6 to 8 senior engineering days to onboarding infrastructure alone. Not architecture work. IAM setup and pipeline walkthroughs.
What self-service infrastructure provisions on AWS
When a developer requests a new environment through a self-serve console, the platform provisions a full isolated stack. Here is what that actually means in AWS terms.
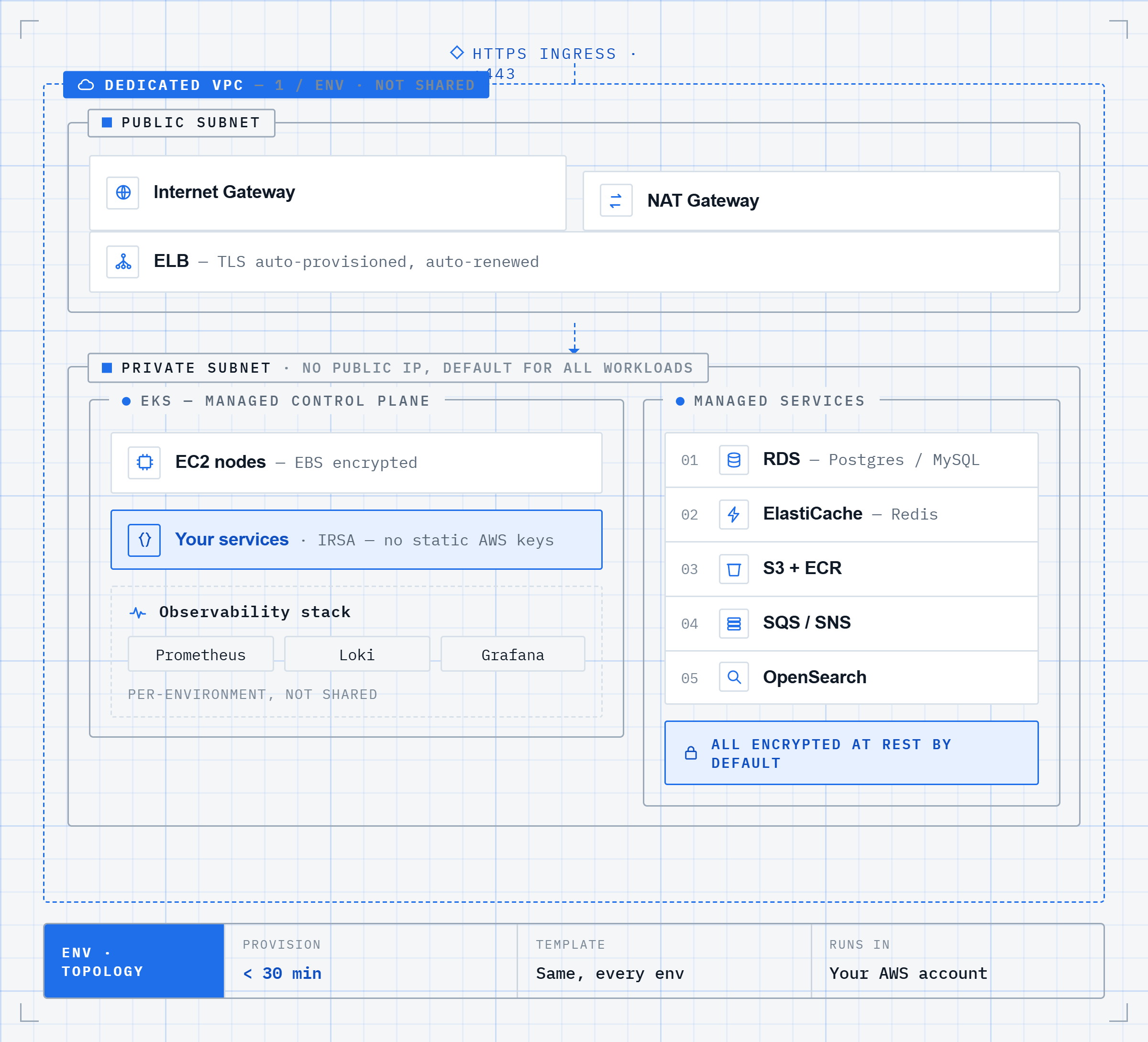
The networking layer comes first
A dedicated VPC per environment with public and private subnets across availability zones, an Internet Gateway, NAT Gateway, and route tables. Every environment gets its own network boundary. Dev, staging, and production are not sharing a VPC with different security group rules trying to simulate isolation. They are genuinely isolated.
Compute and orchestration
An EKS cluster with managed node groups. IRSA (IAM Roles for Service Accounts) configured so each pod gets least-privilege AWS access without static credentials sitting in environment variables. No one on the team writes a Kubernetes manifest or a Helm chart to get here.
Managed services provisioned alongside the cluster, not separately
RDS (Postgres or MySQL) with automated backups, parameter groups configured, and Multi-AZ available for production
ElastiCache for Redis
ECR repository per service for container images
S3 buckets with lifecycle policies
SQS queues where the service needs async processing
Observability included by default
Prometheus, Loki, and Grafana provisioned inside every environment at creation. Logs and metrics are available from the first deployment. No separate Helm chart installation, no persistent storage configuration, no alert rule writing. The monitoring stack is part of the environment, not a follow-up task.
Security defaults applied at provisioning time, not after
VPC isolation, encrypted EBS volumes, encrypted RDS storage, secrets managed via Kubernetes secrets with encryption at rest, RBAC scoped per environment. These are not optional add-ons. They are part of the template.
The whole stack provisions in under 30 minutes. A senior DevOps engineer provisioning the same stack manually takes 4 to 8 hours and produces an environment that may differ from the last one they built.
What growing engineering teams actually gain from self-service
As engineering organizations scale, self-service infrastructure becomes less about convenience and more about maintaining developer velocity.
Faster deployments
Developers can deploy applications without waiting on infrastructure tickets or platform team intervention. Changes move from code review to production faster, reducing lead time and improving release frequency.
More leverage from Platform Engineering
Instead of spending time on repetitive deployment requests, platform engineers can focus on reliability, security, infrastructure standards, developer experience, and long-term architecture improvements.
Consistent cloud environments
Standardized infrastructure provisioning and deployment workflows reduce configuration drift. Development, staging, and production environments become more predictable and easier to manage.
Faster developer onboarding
New engineers can use the same deployment workflows and infrastructure patterns as the rest of the organization. This reduces onboarding friction and shortens time to first deployment.
Better cloud cost management
Self-service platforms create clear ownership around infrastructure resources. Teams gain better visibility into cloud usage, making it easier to track costs, improve accountability, and optimize cloud spend.
Improved engineering scalability
As the number of developers grows, operational workload does not have to grow at the same rate. Teams can support more services and deployments without creating additional coordination overhead.
Scaling delivery without scaling platform headcount
As engineering teams grow, platform teams can quickly become bottlenecks for infrastructure provisioning and deployment requests. Self-service platforms automate these workflows, enabling developers to provision resources independently while maintaining security and governance controls.
As a notification infrastructure provider serving enterprise customers, SuprSend needed a way to deploy its platform within customers’ AWS accounts. By adopting a managed internal developer platform, the company avoided an estimated 12-15 man-months of engineering effort and reduced deployment times to under a day.
How an Internal Developer Platform enables self-service and standardization
Self-service infrastructure does not happen by itself. It requires a platform layer that standardizes how infrastructure is provisioned, how applications are deployed, and how operational controls are enforced. That layer is the Internal Developer Platform (IDP).
An IDP sits between developers and the underlying cloud infrastructure. Developers interact with a self-service interface, Git repository, or deployment workflow. The platform handles the operational complexity underneath, including infrastructure provisioning, Kubernetes configuration, CI/CD automation, secrets management, observability, and access control.
In practice, this is what an IDP looks like:
Connect your cloud account
The platform connects to AWS, Azure, or GCP using secure IAM-based access. Infrastructure is provisioned directly inside your cloud account, ensuring ownership, security, and compliance remain under your control.
Create an environment
Developers select a region and environment type, such as development, staging, or production. The platform automatically provisions the required cloud infrastructure, including networking, Kubernetes clusters, compute resources, container registries, databases, caching layers, logging, monitoring, and alerting systems.
Connect a repository and deploy
A GitHub or GitLab repository is connected to the platform. Developers define the target branch, and every code push triggers an automated deployment workflow. CI/CD pipelines, container image builds, and deployment orchestration are handled automatically.
Operate within guardrails
Developers can provision and manage their own services without requiring elevated cloud permissions. Role-based access control, audit logs, environment isolation, and policy enforcement provide governance without creating operational bottlenecks.
What an IDP does not replace
An Internal Developer Platform automates infrastructure provisioning and application delivery. It does not replace architectural decision-making. Areas such as multi-account cloud strategy, disaster recovery planning, cost optimization, compliance requirements, and cloud governance still require experienced engineering judgment.
FAQs
1.What is self-service deployment?
Self-service deployment is a software delivery approach that enables developers to deploy applications and provision environments without relying on DevOps teams for routine tasks. Using automation, predefined templates, and security guardrails, teams can release software faster while maintaining consistency, compliance, and operational control.
2. How does self-service infrastructure reduce DevOps bottlenecks?
Instead of waiting for infrastructure provisioning or deployment support, developers can perform common operational tasks themselves. This reduces handoffs, shortens deployment cycles, and improves engineering velocity.
3. Why are startups investing in self-service infrastructure?
As engineering teams grow, operational requests grow with them. Self-service infrastructure helps startups scale deployments, environments, and cloud operations without scaling DevOps headcount at the same rate.
4. Can developers deploy without DevOps using self-service infrastructure?
Developers can handle routine deployments and environment management on their own. DevOps teams still play a critical role in defining standards, maintaining platforms, and ensuring reliability at scale.
5. Do startups need an Internal Developer Platform (IDP) for self-service?
Not necessarily, but most self-service initiatives eventually require a platform layer. An Internal Developer Platform provides the workflows, guardrails, and automation needed to make self-service infrastructure work reliably at scale.
Conclusion
Developer self-service infrastructure has become a practical requirement for growing engineering teams.
As the number of developers, services, and deployments increases, relying on manual infrastructure processes creates bottlenecks that slow down delivery. Self-service infrastructure helps teams standardize deployments, reduce operational overhead, and maintain developer velocity as they scale.
While some organizations build these capabilities internally through Platform Engineering, doing so requires significant time and ongoing investment. For many startups and growing teams, a managed Internal Developer Platform can provide the same self-service experience without the effort of building and maintaining the platform themselves.
The goal is not to replace DevOps or Platform Engineering. It is to ensure developers can deploy, provision, and operate services independently while platform teams focus on reliability, security, and architecture.
Ready to see what self-service infrastructure looks like in practice?