
Golden Path Deployments: Ship Faster Without Managing Kubernetes or Terraform
How an internal developer platform removes infrastructure from the developer's critical path



Setting up infrastructure shouldn’t take longer than building the feature.
For engineering teams without a dedicated DevOps function, it often does. Spinning up a new environment means configuring VPCs, provisioning EKS clusters, wiring up monitoring, and writing CI/CD pipelines from scratch. That’s before a single line of application code gets deployed.
The concept of a golden path exists to fix this. A golden path is a standardized, pre-paved route from code to production that removes the guesswork from deployment. An internal developer platform is the mechanism that makes it real.
This post covers what a golden path deployment workflow looks like, how internal developer platforms implement one, and what the right level of abstraction looks like for engineering teams that want to ship faster without taking on unnecessary infrastructure complexity.
TL;DR
A golden path is a standardized, pre-paved route from code to production that removes infrastructure decisions from the developer’s critical path
An internal developer platform is what actually implements it. It provisions environments, automates CI/CD, and handles cloud complexity by default
Building a golden path the traditional way (Backstage + Terraform + ArgoCD) requires a dedicated platform team and 6-18 months of build time
For teams without a dedicated DevOps function, an IDP gives you the same outcome without assembling it yourself
The right IDP doesn’t just abstract Kubernetes and Terraform. It makes every environment identical, every deployment consistent, and observability available from day one
Golden paths are not mandates. The best ones are defaults developers choose because they work
What Is a Golden Path Deployment Workflow in Platform Engineering?
A golden path is a predefined deployment workflow with sensible defaults already configured. Infrastructure provisioned. CI/CD wired. Observability running. The developer pushes code. The platform handles the rest.
Spotify built the concept because their autonomous team model created a different problem. Teams moved fast but independently. There was no standard way to ship a service. If you wanted to know how deployments worked, you asked whoever had done it most recently and hoped their answer still applied.
The fix was a supported, opinionated path from code to production. Not a mandate. A default. The path covered scaffolding, environment setup, CI/CD configuration, and monitoring. Teams could go off it when they needed to. Most didn’t, because the path was faster.
Netflix built the same idea and called it the Paved Road. Different name, same principle: make the right way the easy way.
What both companies had that most SaaS teams don’t is a dedicated platform team maintaining those workflows. Golden paths aren’t a one-time setup. They get versioned, updated, and extended as infrastructure changes. That maintenance work is real and ongoing.
An internal developer platform is how you operationalize a golden path without doing all of that yourself.
From Golden Path to IDP: How the Two Connect
A golden path describes the preferred developer workflow. In platform engineering, an internal developer platform is the automation, self-service tooling, and integrations that make that workflow the default rather than a document people are expected to remember.
How do internally built workflows break?
You can define a golden path without an IDP. Document your Terraform module structure. Standardize your CI templates. Put conventions in Confluence and tell every team to follow them. It holds until someone is under deadline pressure and skips a step. Someone else copies that pattern. Six months later you have three different deployment configurations across five services and no clear owner.
An IDP encodes those decisions into repeatable automation. When a developer connects a GitHub repo and spins up a new environment, the platform provisions a VPC, creates an EKS cluster, configures subnets, deploys Prometheus, Loki, and Grafana, and applies security defaults. The developer doesn’t make those decisions. The platform already made them.
That said, IDPs don’t force uniformity across every service. Mature platforms standardize the baseline and allow explicit variation for different workload types, compliance requirements, or regions. The goal is reducing unmanaged drift, not eliminating all configuration differences.
To build an internal developer platform this way means maintaining Terraform modules, running ArgoCD, operating the Backstage internal developer platform, and owning every integration point connecting all three. Roadie’s analysis of self-hosting Backstage puts the minimum team size at 3 dedicated engineers, with salary and overhead alone running around $450,000 annually, and time to something teams would actually use at 6-12 months.
For a 15-person SaaS team, that’s a significant operational commitment before a single application gets deployed.
How IDP Abstract Cloud Complexity from Application Developers
Abstraction in an IDP isn’t about hiding how infrastructure works. It’s about removing decisions that don’t belong in the application developer’s critical path.
On a team without an IDP, a developer who needs a new service has to answer questions that have nothing to do with the service itself. Which VPC does this go in? What node group size? How does the CI pipeline get wired? Where do logs ship? Who sets up the IAM role? These are solved problems at the infrastructure level. They shouldn’t require a decision every time a new service gets created.
An IDP moves those decisions upstream. The platform team, or in the case of a bought IDP, the vendor, makes those calls once. EKS cluster configuration, VPC topology, subnet layout, observability stack, security group defaults. They get encoded into the environment provisioning layer and applied consistently across every environment.
For example, when you are deploying on AWS, an internal developer platform handles EKS cluster provisioning, VPC configuration, IAM role setup, and observability wiring. Those are decisions the internal developer platform architecture makes once and applies consistently across every environment.
What the developer interacts with is a service abstraction. Define the service type: web service, background worker, cron job. Point it at a GitHub repo and branch. The platform builds the container image, deploys it to the cluster, wires up the load balancer, and starts routing traffic. By default, no Dockerfile is required. Teams that need custom build behavior can bring their own container image instead.
This is the right abstraction level for application developers. They retain full visibility into what’s running. Logs, metrics, and deployment history are accessible. But the infrastructure layer that doesn’t change between services is handled by the platform, not re-solved by each team independently.
The escape hatch matters too. When a team needs something outside the standard baseline, a custom RDS configuration or a specific SQS queue setup, the platform exposes VPC and subnet IDs so teams can extend using their own Terraform or Pulumi scripts without disrupting what the platform already manages.
What Is the Right Level of Abstraction in an IDP?
Too little abstraction and the IDP is just a thin wrapper around Kubernetes that still requires developers to understand node groups, ingress controllers, and Helm chart structure. Too much and developers lose visibility into what’s actually running, which makes debugging production incidents harder than it needs to be.
The right level is where infrastructure decisions that are identical across services get made once by the platform, and decisions that are legitimately different per service stay with the developer.
The line between these two isn’t fixed. It shifts based on team size, compliance requirements, and how much infrastructure variation a team legitimately needs. A fintech team running in a regulated environment will need more explicit control over networking and access policies than a team running a standard web API.
What matters is that the boundary is explicit. When developers don’t know where their responsibility ends and the platform begins, you get both: developers making infrastructure decisions they shouldn’t have to make, and platform teams fielding support tickets for things that should have been self-service.
A clear shared responsibility model fixes this. Here’s how LocalOps defines that boundary.
How IDPs Balance Developer Autonomy with Infrastructure Standardization
This is where golden paths either work or fall apart. Standardize too hard and developers work around the platform. Give too much freedom and you’re back to every team running their own infrastructure setup with no consistency across environments.
The way most IDPs resolve this is through opinionated defaults with explicit escape hatches. The platform makes the common case easy and the uncommon case possible, without making the uncommon case the default.
In practice this means three things.
The standard path covers the majority of workloads. Web services, background workers, cron jobs, and scheduled tasks all deploy through the same pipeline without any custom configuration. A developer shouldn’t need to touch infrastructure to ship any of these.
When a team has a legitimate reason to go off the golden path, the platform provides extension points rather than hard limits. Exposing VPC and subnet IDs so teams can provision their own RDS instances or SQS queues using Terraform is an example of this. The platform manages what it provisions. The team manages what they add. Both sets of resources sit inside the same network boundary.
Role-based access keeps the right people in control of the right things. Not every developer needs production deploy permissions. Not every engineer needs access to infrastructure configuration. The IDP enforces those boundaries without requiring a manual access review every time someone joins the team.
The outcome isn’t uniformity. It’s consistency at the infrastructure layer and autonomy at the application layer. Teams make decisions about how their service behaves. The platform makes decisions about how infrastructure gets provisioned and secured. Those two concerns stay separate.
What Actually Changes for a Developer When an IDP Implements the Golden Path
The easiest way to understand what an IDP delivers is to walk through what a developer actually does differently.
Without a golden path, spinning up a new service looks like this. The developer checks what the last team did, finds a repo with a vaguely similar setup, copies the Terraform, adjusts the variables, hopes the VPC IDs are still valid, writes a Dockerfile, figures out the CI pipeline configuration, sets up IAM roles, and then manually wires up monitoring after the first deployment. That process takes days. Sometimes weeks. And it produces another slightly different configuration that the next person will copy.
With an IDP implementing the golden path, the same developer creates a service, select the service type, point it at a GitHub repo and branch. The platform builds the container image without a Dockerfile. The first git push deploys the service. Prometheus is already scraping metrics. Loki is collecting logs. Grafana has a dashboard.
The whole thing takes under 30 seconds.
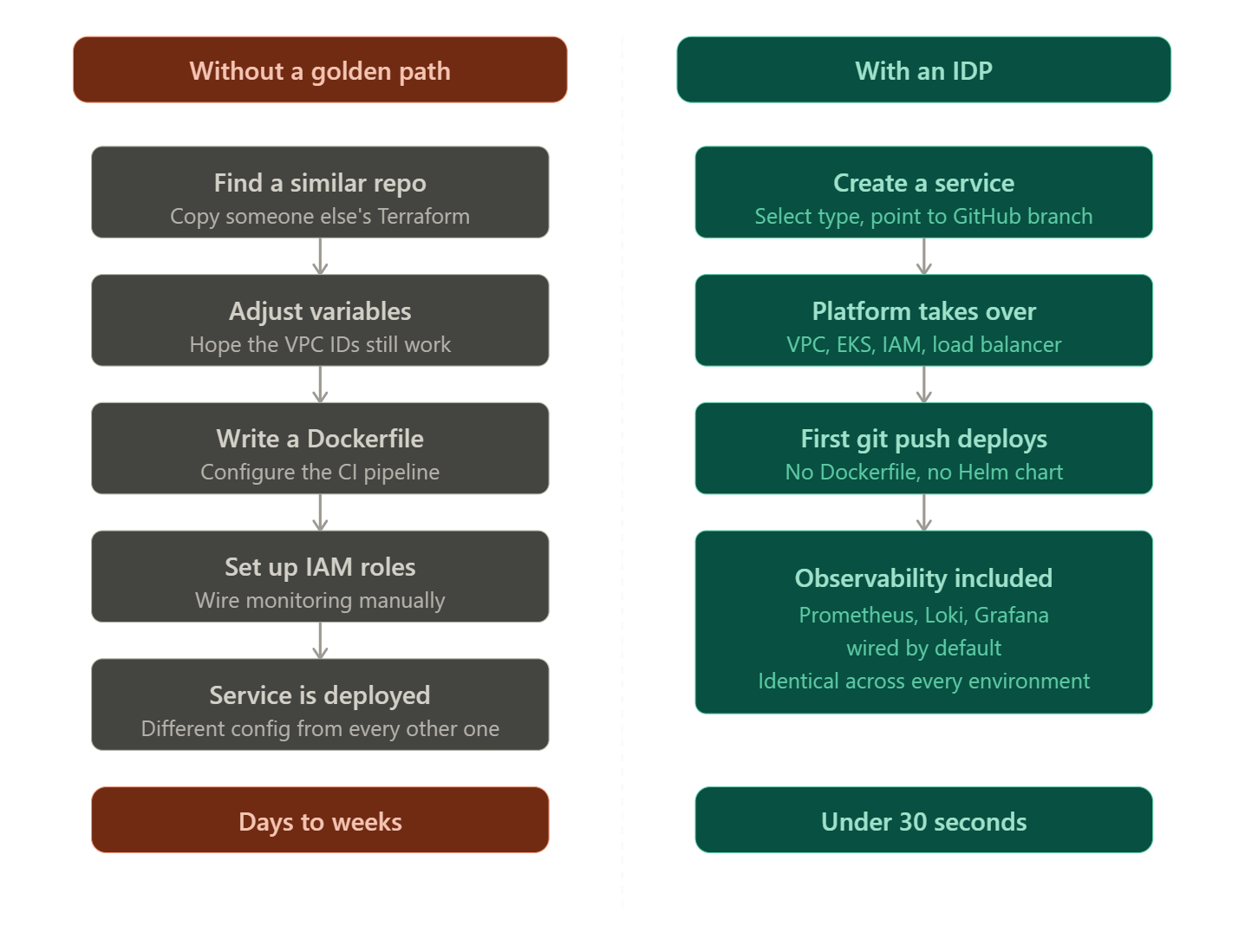
No Kubernetes manifest written. No Terraform module copied and modified. No DevOps engineer pulled into a provisioning task. No staging environment that diverges from production because someone tweaked it manually.
The developer’s job is to write application code and push it. The platform’s job is everything else on the golden path. That separation is what the title of this post is actually about.
Every team’s setup is different. If you want to see how this maps to your specific stack, LocalOps engineers can walk through it with you.
How to Standardize Deployments Across Engineering Teams Without Slowing Them Down
The standardization problem at scale isn’t philosophical. It’s operational. When five teams deploy five different ways, debugging a production incident means understanding five different pipeline configurations before you can even start looking at the application.
Environment drift is where this compounds. Team A’s staging environment has a different EKS node group configuration than production because someone changed it manually six months ago and nobody updated the baseline. Team B’s worker service has a different IAM role structure because it was set up by an engineer who has since left. None of this is visible until something breaks.
A golden path enforced by the platform eliminates this class of problem. Every environment is provisioned from the same template: dedicated VPC, private and public subnets with consistent CIDR ranges, EKS cluster with the same node configuration, Prometheus and Loki wired to the same Grafana instance. Differences between environments are explicit parameters, instance size, replica count, backup policy, not untracked manual changes.
Deployment pipelines follow the same principle. One artifact gets built per commit. That artifact gets promoted through environments. The pipeline configuration doesn’t live in a per-team CI script that diverges over time. It lives in the platform.
The compounding effect matters too. Every service that follows the golden path is one less snowflake configuration for the next engineer to reverse-engineer. At 5 services that’s manageable. At 50 it’s the difference between a team that can debug incidents quickly and one that can’t.
The 2024 DORA State of DevOps report found that best internal developer platforms reduce cognitive load and create standardized paths to production. Teams using mature platforms report faster onboarding and more consistent deployment practices across services.
SuprSend estimated replicating standardized deployment infrastructure for BYOC in-house would have taken 10 to 12 person-months of engineering effort. This figure is from CTO Gaurav Verma, but the cost structure is real regardless of the specific number. Read the full case study.
How the Golden Path Handles Day Two Operations
Most golden path content stops at first deployment. The service is running. The pipeline works. That’s where the documentation ends.
Day two is where things get real. A service starts returning HTTP 500s at 2am. A background worker is consuming more memory than the node can handle. A deployment goes out and latency spikes. Someone needs to roll back but isn’t sure which commit to target.
Without a golden path, each of these scenarios requires a different investigation path depending on how that service was deployed and by whom. With a golden path enforced by the platform, the answer is always in the same place.
Logs are in Loki. Metrics are in Prometheus. Both are accessible from the same Grafana dashboard that every environment gets by default. The on-call engineer doesn’t need to know which team built the service or how they set up monitoring. The observability stack is identical across every environment because the platform provisioned it the same way every time.
Rollbacks follow the same principle. Every deployment is triggered by a git commit. Rolling back means redeploying a previous commit from the same pipeline. No custom rollback scripts. No manual kubectl commands. The same path that deployed the service is the path that rolls it back.
Scaling is handled at the platform layer too. Auto-scaling is configured by default. The developer sets resource limits and replica counts as service parameters. The platform manages the rest.
Day two operations are where the golden path pays back the most. The initial deployment is a one-time event. Debugging, scaling, and rolling back happen repeatedly. A platform that makes those operations consistent across every service is worth more than one that just makes the first deploy fast.
Golden Path: Build It Yourself vs Let the IDP Handle It
Here’s what implementing a golden path looks like across both approaches:
Even at 150+ engineers, the answer isn’t necessarily to build everything. The practical approach is to buy the infrastructure layer, environment provisioning, CI/CD, observability, security defaults, and build on top of it for the parts that are genuinely specific to your organization. Custom compliance workflows, internal service catalogs, bespoke access policies. The IDP handles the golden path baseline. Your platform team owns what sits above it. That split lets a growing engineering org add platform capability incrementally without starting from zero on infrastructure every time the team scales.
FAQs
1. What is the difference between an internal developer portal vs platform in a golden path setup?
A portal is a UI. It surfaces a service catalog, documentation, and self-service actions. Backstage is the most common example. A platform is the infrastructure layer underneath: environment provisioning, CI/CD, access control, observability. In a golden path context, the portal is how developers interact with the path. The platform is what runs it. A portal without a platform gives developers a nice interface to request things that still take two weeks to get. The platform is what makes the golden path execute automatically.
2. How does an open source internal developer platform like Backstage compare to an IDP for golden path delivery?
Backstage doesn’t provision infrastructure. It doesn’t manage EKS clusters, configure VPCs, or wire up Prometheus. It gives you a service catalog and a scaffolding framework. To get a working golden path out of Backstage, you still need Terraform for infrastructure, ArgoCD for deployments, and a monitoring stack. Then you need engineers to maintain all three plus the integration layer connecting them. A purpose-built IDP ships all of that as one product. The golden path is the default behavior, not something you assemble. Build time with Backstage: 6-12 months minimum. With an IDP: under 30 minutes for a production-grade environment.
3. What is the difference between a golden path and a CI/CD pipeline?
A CI/CD pipeline handles build and deployment automation for a single service. A golden path covers the full journey: environment provisioning, infrastructure configuration, CI/CD setup, observability, and security defaults. The pipeline gets code deployed. The golden path ensures everything around that deployment is consistent and repeatable across every service and team.
4. Does using an IDP mean you lose control over your infrastructure?
No. A well-designed IDP makes the boundary explicit. The platform owns what it provisions: the VPC, the cluster, the observability stack, the security defaults. The team owns everything built on top of it. Most IDPs expose extension points, VPC IDs, subnet IDs, environment tags, so teams can provision additional resources using their own Terraform or Pulumi scripts inside the same network boundary. The platform manages its layer. The team manages theirs. What you give up is the need to make the same infrastructure decisions repeatedly. What you keep is full visibility and control over your application layer and any custom infrastructure your team adds.
5. When does an engineering team need a golden path and an internal developer platform to support it?
Three signals. Deployments are inconsistent across services and debugging a production incident means reverse-engineering someone else’s pipeline before you can even look at the application. New engineers take two weeks to ship their first change because there’s no documented, working path from code to production. Infrastructure setup is gated on one or two people and every new service requires a coordination round before it can deploy. Any one of these means the team is operating without a golden path. An IDP is how you implement one without a 6-12 month platform build first.
Conclusion
The golden path concept is simple. Make the right way the easy way. The hard part is implementation.
For large engineering organizations with dedicated platform teams, building a golden path in-house is a reasonable investment. They have the headcount, the runway, and the complexity that justifies it. For everyone else, assembling Backstage, Terraform, ArgoCD, and a monitoring stack and maintaining the integration layer between them is a significant engineering commitment that compounds over time.
The more useful question for most engineering leaders isn’t whether to have a golden path. It’s whether to build the platform that delivers it or use one that already does.
An IDP doesn’t replace engineering judgment. It removes the infrastructure decisions that don’t require it. VPC configuration, EKS provisioning, CI/CD pipeline setup, and observability wiring are solved problems. They shouldn’t consume engineering cycles on every new service or environment.
The teams that ship fastest aren’t the ones with the most DevOps expertise distributed across every developer. They’re the ones that encoded that expertise into a platform and got their developers back to writing business code.
If your team is spending more time on infrastructure setup than on the product itself, that’s the signal. A golden path won’t write your code. But it will stop infrastructure from being the reason it doesn’t ship.
If you’re figuring out how this would fit into your setup, then LocalOps team can help you work through it:
Book a Demo - Walk through how environments, deployments, and AWS infrastructure are handled in practice for your setup.
Get started for free - Connect an AWS account and stand up an environment to see how it fits into your existing workflow.
Explore the Docs - A detailed breakdown of how LocalOps works end-to-end, including architecture, environment setup, security defaults, and where engineering decisions still sit.