
Open-Source Heroku Alternatives: What Works in Production and What Doesn't
Thinking of using open-source Heroku alternatives for production? Here’s what works, what doesn’t, and the real cost most teams miss.



TL;DR
What this covers: What open-source Heroku alternatives actually deliver in production versus in demos, the real build-versus-buy cost of running a self-hosted alternative when engineering hours and on-call burden are included, and the long-term architectural risks that engineering leaders accept when choosing between a managed PaaS and a self-hosted cloud-native IDP.
Who it is for: CTOs and VPs of Engineering evaluating Heroku alternatives in 2026, specifically teams that have looked at Coolify, Dokku, Caprover, or CapRover and are trying to determine whether the open-source route is the right call for a production workload.
The conclusion: Open-source Heroku alternatives are genuinely good for specific use cases: small teams, internal tooling, hobby workloads, and teams with a dedicated platform engineer who wants full control over every configuration surface. For scaling SaaS teams with production reliability requirements, enterprise compliance obligations, and engineering organisations where platform maintenance competes with product development for senior engineering hours, the total cost of a self-hosted alternative consistently exceeds that of a managed cloud-native IDP, once all hours are included. This guide shows exactly where costs accumulate and what the architectural risks look like over a three-year horizon.
Evaluating whether to build or buy your platform?
→ See how a production-ready AWS environment is set up in 30 minutes
The Open-Source Heroku Alternative Landscape in 2026
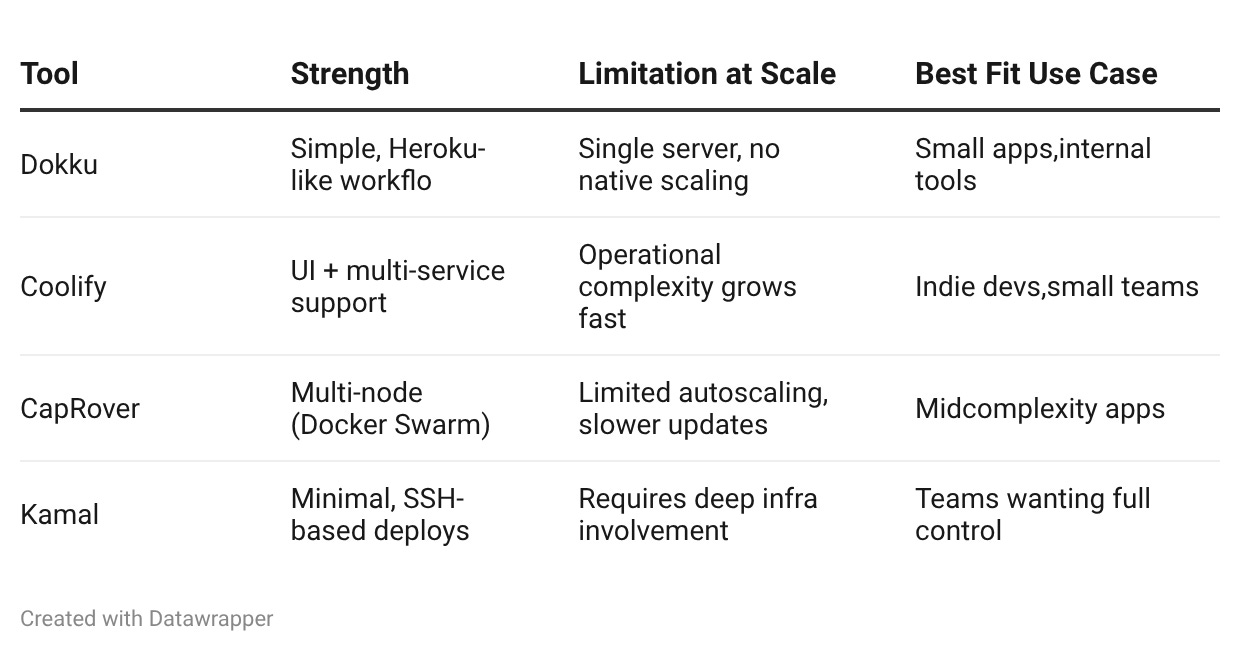
The field of open-source Heroku alternatives is active and well-populated. Teams evaluating the category in 2026 have meaningful options, each with a different point of view on how to replicate Heroku’s developer experience on self-hosted infrastructure.
Dokku is the oldest and most established option. It describes itself as a “Docker-powered mini-Heroku” and implements the Heroku buildpack interface on a single server. Push to a Git remote, Dokku builds and deploys. The operational model is close to Heroku for simple applications. The scaling model, Dokku, runs on a single server, which is the primary limitation.
Coolify is the most actively developed option in 2026. It provides a web UI for managing applications, databases, and services across multiple servers. It supports Docker Compose deployments and has grown its feature set significantly. It has a strong following among indie developers and small teams.
CapRover sits between Dokku and Coolify in complexity. It runs on Docker Swarm, supports multiple nodes, and provides a dashboard for application management. It is more capable than Dokku for multi-service architectures but less actively developed than Coolify.
Kamal (formerly MRSK, from the Rails team at 37signals) takes a different approach: it deploys Docker containers to bare servers using SSH, with zero platform software running on the target servers. It is a deployment tool more than a platform, and it requires more operational involvement than the others.
Each of these tools has genuine strengths. None of them is a complete substitute for Heroku at the production scale for a B2B SaaS team with reliability requirements and enterprise customers. The gap between what they demonstrate in a tutorial and what they require in production is where the real evaluation happens.
Want to skip managing platform layers entirely?
→ Explore how LocalOps handles infrastructure, deployments, and observability on AWS
What Open-Source Heroku Alternatives Actually Deliver in Production
The honest evaluation of open-source Heroku alternatives requires separating two distinct questions: what do they deliver at initial setup, and what do they require to operate reliably at production scale over time?
The initial setup story for most open-source Heroku alternatives is genuinely good. Dokku on a DigitalOcean droplet or a small EC2 instance can be running and deploying applications within an hour. Coolify’s setup process is well-documented and fast. For a team deploying a single application with a Postgres database and basic monitoring, these tools deliver the Heroku-like experience they promise.
The production-scale story is where the honest picture diverges from the tutorial experience.
What works well in production:
Single-server deployments for low-traffic applications. Dokku and Coolify are reliable for applications that fit on a single server with headroom. Internal tools, admin dashboards, low-traffic marketing sites, and development environments run well on these platforms. The operational model is simple because the infrastructure is simple.
Teams with a dedicated platform engineer. Open-source Heroku alternatives work in production when there is a person on the team whose job it is to maintain the platform, respond to platform failures, and keep the underlying infrastructure patched and healthy. The platform does not manage itself; it requires ownership. When that ownership is clearly assigned, and the person has the skills to carry it, these tools can support meaningful production workloads.
Non-critical workloads where downtime is acceptable. Tools, demos, staging environments, and internal services where an hour of downtime does not translate directly to customer impact or revenue loss tolerate the failure modes of self-hosted platforms better than customer-facing production services do.
What breaks or degrades at the production scale:
Multi-node reliability. Dokku is fundamentally a single-server platform. Dokku Scheduler plugins exist to add Kubernetes or Nomad scheduling, but they add significant operational complexity and are not production-proven at the same level as the core Dokku runtime. Coolify’s multi-server support is functional but has more surface area for failure than a managed Kubernetes cluster operated by a team with dedicated expertise.
Automatic failover. When the server running a Dokku deployment fails, the application goes down. Bringing it back up requires either manual intervention or a separately built and maintained automated recovery system. Heroku handles dyno failure transparently. Managed Kubernetes on EKS handles pod failure transparently. Self-hosted platforms without a managed control plane require explicit failover engineering.
Observability at scale. The default observability story for most open-source Heroku alternatives is thin. Coolify provides basic container metrics. Dokku provides application logs through dokku logs. Neither provides the integrated metrics collection, log aggregation, and dashboard correlation that production incident response requires. Teams running these platforms in production typically assemble a separate observability stack, Prometheus, Loki, and Grafana, on top of the platform, which is the same assembling problem that Heroku’s add-on model creates, shifted from a managed service to a self-hosted infrastructure project.
Security patching cadence. Open-source platforms run on servers that require OS-level patching, Docker runtime updates, and platform software updates. These updates need to happen on a cadence that matches the vulnerability disclosure cycle, which is roughly continuous. On a managed platform, Heroku or a cloud-native IDP, the platform team handles this. On a self-hosted alternative, someone on the engineering team handles it. That someone is typically the same person who handles production incidents, infrastructure changes, and developer support requests.
The Real Operational Limitations of Open-Source Heroku Alternatives
This is the gap between what open-source Heroku alternatives promise and what they deliver for scaling startup teams, and it is worth examining each limitation specifically rather than in aggregate.
Limitation 1: Scaling models that don’t match production workload patterns.
Dokku scales vertically by default: increase the server size to handle more load. Horizontal scaling in Dokku requires additional configuration and is not automatic. Coolify and CapRover support Docker Swarm for multi-node deployments, but Docker Swarm’s autoscaling model is limited compared to Kubernetes’ Horizontal Pod Autoscaler.
For workloads with variable traffic, B2B SaaS applications that peak during business hours, consumer applications with campaign-driven spikes, and any application with non-linear load patterns, the inability to autoscale horizontally based on real-time resource metrics is a meaningful operational gap. Teams either overprovision the server (paying for idle capacity continuously) or accept that traffic spikes will cause degraded performance until someone manually adjusts the infrastructure.
Limitation 2: Database management is the team’s responsibility.
Heroku Postgres is a managed database: provisioning, backups, point-in-time recovery, connection pooling, version upgrades, and failover are handled by the platform. Open-source Heroku alternatives do not provide managed databases. Coolify can deploy a Postgres container; it does not manage it the way Heroku Postgres or Amazon RDS does.
Running a production Postgres database correctly, with automated backups, point-in-time recovery, failover, connection pooling, and a maintenance window strategy for version upgrades, is a non-trivial operational project. Teams that migrate to an open-source Heroku alternative and bring their Postgres database with them are taking on database operations as an engineering responsibility. For teams without database operations expertise, this is where production incidents happen.
Limitation 3: SSL, networking, and security configuration are manual and ongoing.
Heroku handles SSL termination, HTTP-to-HTTPS redirection, and TLS certificate renewal automatically. Open-source alternatives handle this through Let’s Encrypt integration (Coolify, Dokku, and CapRover all support this), but certificate renewal failures, DNS configuration errors, and networking changes are the team’s operational responsibility.
At low service count, this is manageable. As the service count grows, ten, fifteen, twenty services, the surface area for SSL and networking configuration errors grows proportionally. Each service is an additional certificate to renew, an additional DNS record to maintain, and an additional networking configuration that can drift from the intended state.
Limitation 4: No compliance posture for enterprise customers.
Open-source Heroku alternatives running on a VPS or small EC2 instance do not provide the compliance infrastructure that enterprise procurement requires: dedicated VPC, IAM-based access control with audit logs, network isolation between services, data residency in a specified region, and evidence of SOC 2 or equivalent security posture.
For B2B SaaS teams without enterprise ambitions, this may not matter today. For teams with any enterprise go-to-market motion, the infrastructure needs to satisfy the security questionnaire that accompanies every significant deal. An application running on a Coolify-managed Docker host cannot answer that questionnaire honestly. The compliance gap that exists on Heroku also exists on most open-source Heroku alternatives, and in some cases is larger, because self-hosted infrastructure adds an operational attack surface that managed platforms control more tightly.
These are the exact gaps teams hit at scale
→ Talk to an engineer about how teams move off self-hosted setups without downtime
When should a scaling startup choose a managed cloud-native IDP instead?
The decision point is not binary, but there are clear signals that the open-source route is the wrong call for a specific team:
The team has more than five engineers, and product development competes directly with platform maintenance for senior engineering time
The product has enterprise customers or is actively pursuing enterprise deals that will require security questionnaire responses.
The application has stateful workloads, background job queues, WebSocket connections, and large file processing, which require reliable persistent compute
The team does not have a designated platform engineer with Kubernetes or Docker Swarm expertise.
Production downtime directly impacts customer experience, SLAs, or revenue
At any of these signals, the TCO analysis for a self-hosted alternative consistently comes out worse than a managed cloud-native IDP when all costs are included. The following section works through why.
The True Build-Versus-Buy Cost of a Self-Hosted Heroku Alternative
This is the analysis that most engineering teams do not complete before choosing the open-source route, and the one that produces the most surprises when they do it retrospectively after six months of operation.
The surface-level cost comparison is straightforward: open-source Heroku alternatives are free to use, so the cost is just the infrastructure. A $40/month DigitalOcean droplet or a small EC2 instance is dramatically cheaper than Heroku’s production dyno tiers. The analysis looks obvious.
The cost that does not appear in that comparison is engineering time, for initial setup, for ongoing maintenance, for incident response, and for the opportunity cost of senior engineers spending hours on platform work instead of product development.
The initial setup cost:
Setting up a production-grade self-hosted Heroku alternative takes longer than tutorials suggest. The tutorial path, Dokku on a droplet, one application deployed, is genuinely fast. The production path, multi-server setup, managed database configuration, observability stack, SSL and networking configuration, backup verification, monitoring and alerting, runbook documentation, takes a senior engineer two to four weeks of focused effort.
For a company with fifteen engineers at an average fully-loaded cost of $200,000/year, a senior engineer costs approximately $100/hour. Two weeks of setup at 40 hours per week is $8,000. Four weeks is $16,000. This is the upfront engineering investment before the platform serves a single production request.
Most teams do not account for this cost because it feels like infrastructure work rather than a direct expenditure. It appears in sprint velocity metrics as product features not shipped. It does not appear in the infrastructure budget.
The ongoing maintenance cost:
After initial setup, a self-hosted Heroku alternative requires continuous maintenance. Security patches for the host OS, Docker runtime, and platform software need to be applied on a regular cadence. The observability stack needs to be maintained. SSL certificates need to be monitored. Backup integrity needs to be verified periodically. Capacity needs to be reviewed as the application grows.
Conservative estimate for a production self-hosted setup: two to four hours of platform maintenance per week. At $100/hour for a senior engineer, that is $800–$1,600/month in ongoing maintenance cost, consistently, before any incidents occur.
Over twelve months, the maintenance cost alone is $9,600–$19,200. This is in addition to the infrastructure cost, and it compounds with the service count as the platform’s surface area grows.
The on-call burden:
Self-hosted platforms fail in ways that managed platforms handle transparently. A pod crash on EKS restarts automatically. A disk filling on a self-hosted Coolify instance takes the application down until someone investigates and resolves it. A networking configuration change that breaks SSL certificate renewal on a Dokku server causes downtime until someone diagnoses and fixes it.
Production incidents on self-hosted infrastructure happen at off-hours with the same frequency as on managed platforms. The difference is who responds. On Heroku or a managed IDP, Heroku’s reliability team or the IDP provider’s on-call rotation handles infrastructure incidents. On a self-hosted alternative, someone from the engineering team handles them.
At a company with one person effectively on-call for the platform, this represents a meaningful quality-of-life cost that compounds into retention risk over time. Senior engineers who regularly wake up at 2 AM for platform incidents that managed infrastructure would have handled automatically do not stay in that role indefinitely.
The opportunity cost: what the platform engineer is not building.
This is the largest and least visible cost component. Every hour a senior engineer spends on platform maintenance, incident response, and infrastructure configuration is an hour not spent on the product features, performance improvements, and technical debt reduction that drive business value.
For a team at Series A with a product roadmap full of competitive priorities, redirecting a senior engineer’s capacity toward platform maintenance is a strategic cost that appears nowhere in the infrastructure budget and shows up instead in delayed product releases and compressed competitive advantage.
The full cost comparison:
The Long-Term Architectural Risks of Each Path
This is the analysis that matters most for engineering leaders making a three-year infrastructure bet. The day-one costs are relatively predictable. The long-term architectural implications of the hosting choice shape the company’s technical trajectory in ways that are harder to reverse than they appear at the decision point.
Risk Profile 1: Managed PaaS Heroku Alternatives (Render, Railway, Fly.io)
Managed PaaS alternatives to Heroku provide a genuine improvement on Heroku’s developer experience in some areas and similar constraints in others. They are worth examining honestly as a category before discussing the IDP path.
What improves over Heroku: Better pricing models in most cases, better geographic distribution options, more modern infrastructure primitives, and more active product development. Render and Railway, in particular, have improved the developer experience meaningfully relative to Heroku.
What does not improve: The fundamental architecture remains the same. The application runs on the provider’s infrastructure, not in the team’s cloud account. The compliance posture is governed by the provider’s security posture, not the team’s. Infrastructure control is limited by what the provider exposes. The vendor dependency is as deep as Heroku’s, in some cases, deeper, because modern PaaS platforms have fewer migration paths than Heroku did.
The long-term architectural risk: Three years into using a managed PaaS alternative, the team has made application architecture decisions shaped by the platform’s constraints, built deployment workflows around the platform’s model, and accumulated operational familiarity with a platform that may change pricing, deprecate features, or change ownership. The compliance and infrastructure control limitations that eventually drove the team off Heroku are structurally present in every managed PaaS alternative. The team is on a path that leads back to the same decision in a different form.
Risk Profile 2: Self-Hosted Open-Source Alternatives (Coolify, Dokku, Caprover)
Self-hosted alternatives transfer the operational risk from the vendor to the engineering team. This is a genuine benefit for teams with the expertise and capacity to absorb it. For most scaling SaaS teams, it is a risk transfer that creates more exposure than it eliminates.
The platform drift risk: Open-source platforms are maintained by communities with priorities that may not align with the production requirements of a scaling SaaS company. Coolify’s roadmap is driven by its maintainers’ priorities, not by what the teams running it in production need. A critical security vulnerability in an open-source platform’s dependency may be patched in weeks or months, not hours, as a commercial managed platform provider would address it. Teams running production workloads on open-source platforms accept that the platform’s maintenance cadence is outside their control.
The expertise dependency risk: Self-hosted platforms run reliably when someone on the team understands them deeply. That expertise lives in a person, not in the platform. When the person who set up and maintains the Dokku or Coolify installation leaves the company, the institutional knowledge leaves with them. The team inherits a production system they did not build, with configuration choices they do not fully understand, running on infrastructure they now own completely. This is a common and underappreciated operational risk for engineering-led companies.
The scale ceiling risk: Open-source Heroku alternatives have natural scale ceilings that are lower than the scale ceilings of Kubernetes-native platforms. Dokku hits its ceiling at single-server scale. Coolify and CapRover on Docker Swarm hit their ceiling below what a mid-sized production workload on EKS handles routinely. Teams that choose a self-hosted alternative may find themselves re-platforming again within two to three years as the workload outgrows the platform’s scaling model. Re-platforming has a cost that compounds with each cycle, and it diverts engineering capacity from product development at exactly the growth stage where product velocity matters most.
Risk Profile 3: Cloud-Native IDP on Your Own AWS Account (LocalOps)
The long-term architectural risk profile of a cloud-native IDP differs from both managed PaaS and self-hosted alternatives in one structural dimension: the infrastructure lives in the team’s AWS account.
What this means for long-term risk: The vendor dependency is on the IDP’s operational interface, the deployment experience, the observability dashboards, and the environment management UI, not on the infrastructure itself. If the IDP provider changes pricing, changes the product, or ceases operation, the EKS cluster, RDS databases, ElastiCache instances, and S3 buckets continue running in the team’s AWS account. The migration path is to adopt a different operational interface on top of the same infrastructure, not to re-platform the infrastructure from scratch.
The compliance posture compounds positively: An application running on AWS-native infrastructure inside the team’s own VPC, with IAM-based access control and AWS-native audit logging, starts from a compliance posture that can support enterprise customers from day one. As the company grows and enterprise procurement becomes more rigorous, the infrastructure posture improves by configuration, enabling additional AWS compliance features, adding audit log retention, enabling GuardDuty, rather than by platform migration.
The scale ceiling is the AWS scale ceiling: EKS scales to the capacity of the AWS region. There is no platform-imposed scale ceiling below the hyperscaler ceiling. Teams that grow from five services to fifty services, from one AWS region to three, and from $1M ARR to $100M ARR do not re-platform their infrastructure along the way; they scale the same Kubernetes and AWS-native services that were there from the beginning.
The architectural risk to manage: The risk of a cloud-native IDP path is primarily in the initial adoption decision: choosing a provider whose infrastructure model, pricing, and roadmap alignment fit the team’s three-year trajectory. This risk is manageable through due diligence at the selection point, examining the IDP’s architecture (does infrastructure live in your account?), pricing model (does cost scale reasonably with your workload growth?), and migration path (what happens if you need to change providers?).
How LocalOps Addresses the Build-Versus-Buy Decision
LocalOps is an AWS-native Internal Developer Platform that resolves the build-versus-buy tension for scaling SaaS teams, replacing Heroku.
The build case for a self-hosted alternative rests on cost and control. LocalOps preserves both while eliminating the engineering overhead of operating the platform. Infrastructure runs in the team’s AWS account, with full VPC control, full IAM visibility, and full compliance posture. The platform fee replaces the engineering hours that self-hosted alternatives require.
The buy case for a managed PaaS rests on simplicity and developer experience. LocalOps matches the simplicity of managed PaaS, push to branch, service deploys, logs and metrics are immediately available, without the compliance constraints and infrastructure opacity that come with a provider-owned cloud environment.
Connect your AWS account. Connect your GitHub repository. LocalOps provisions a dedicated VPC, EKS cluster, load balancers, IAM roles, and a complete observability stack automatically. No Terraform. No Helm charts. First environment ready in under 30 minutes. No platform maintenance, no on-call burden for infrastructure incidents, no observability setup project.
The infrastructure stays in the team’s AWS account permanently. The engineering hours that a self-hosted alternative would consume go back to the product roadmap.
“Their thoughtfully designed product and tooling entirely eliminated the typical implementation headaches. Partnering with LocalOps has been one of our best technical decisions.” — Prashanth YV, Ex-Razorpay, CTO and Co-founder, Zivy
“Even if we had diverted all our engineering resources to doing this in-house, it would have easily taken 10–12 man months of effort, all of which LocalOps has saved for us.” — Gaurav Verma, CTO and Co-founder, SuprSend
Frequently Asked Questions
When is Dokku or Coolify the right answer for a production workload?
Dokku and Coolify are the right answer when the workload is genuinely simple, the team has a dedicated platform engineer with operational enthusiasm, and downtime does not directly impact customer experience or revenue. Internal tools, admin dashboards, low-traffic APIs, and development environments are well-served by open-source alternatives. The wrong answer is applying these tools to customer-facing production services at Series A scale without accounting for the operational cost of running and maintaining the platform under real production conditions.
What is the most common failure mode when teams self-host a Heroku alternative in production?
The most consistent failure mode is not a technical failure; it is an expertise departure. The engineer who set up and understood the self-hosted platform leaves the company. The team inherits a production system with undocumented configuration choices, dependency versions that have drifted from the original setup, and no institutional knowledge of why specific decisions were made. Recovering from this situation typically requires a platform audit, a re-provisioning project, and several weeks of senior engineering time, at a moment when that time is usually least available. Managed platforms eliminate this risk category because the platform knowledge lives in the provider’s team, not in a single employee.
How does the compliance posture of self-hosted alternatives compare to LocalOps on AWS?
Self-hosted Heroku alternatives running on a VPS or small EC2 instance have a weaker compliance posture than applications running in a properly configured AWS VPC on LocalOps. VPC isolation, IAM-based access control, audit logging, and data residency are native features of the AWS environment that LocalOps provisions automatically. On a self-hosted alternative, these capabilities require explicit engineering work to implement, document, and maintain. For B2B SaaS teams pursuing enterprise customers, the compliance gap between a self-hosted alternative and an AWS-native IDP is the compliance gap between infrastructure that fails a security questionnaire and infrastructure that passes one.
What does the migration path look like if a team wants to move from Coolify or Dokku to LocalOps?
The migration involves three steps: containerising any applications that are not already containerised (most Dokku-deployed applications are Heroku-buildpack-based and require Dockerfiles), migrating managed services (Postgres to RDS, Redis to ElastiCache), and connecting the GitHub repository to LocalOps for automated deployments. LocalOps provides the environment infrastructure automatically, VPC, EKS cluster, load balancers, IAM roles, observability stack, so teams are not building the AWS environment from scratch. The migration from a self-hosted alternative to LocalOps is typically faster than the original setup of the self-hosted alternative, because LocalOps automates the infrastructure provisioning that the self-hosted setup required manual work to achieve.
Is the open-source alternative path ever cheaper than a managed IDP over a three-year horizon?
For teams with a dedicated platform engineer whose primary role is infrastructure operations and whose time is not competing with product development, the total cost of ownership for a well-run self-hosted alternative can match or slightly undercut a managed IDP over three years. This is the scenario where the build path makes financial sense: the engineering cost is already allocated to infrastructure work, and the open-source alternative gives that engineer maximum control. For teams where the platform engineer is also a product engineer, where platform maintenance competes directly with feature development, the open-source path is more expensive over a three-year horizon in every realistic model. The engineering opportunity cost of platform maintenance consistently exceeds the managed IDP’s platform fee.
What architectural signals indicate that a team has outgrown its self-hosted Heroku alternative?
The clearest signals are: traffic spikes that cause degraded performance because autoscaling is not available or not automatic, incident response time that is measured in hours rather than minutes because platform observability is insufficient, security questionnaire line items that cannot be answered honestly because the infrastructure lacks VPC isolation and IAM controls, and deployment pipelines that require manual steps because the CI/CD integration on the self-hosted platform does not support the team’s Git workflow. Any one of these signals is worth evaluating against the TCO comparison above. Multiple signals simultaneously indicate that the re-platforming project will be more costly the longer it is deferred.
Key Takeaways
Open-source Heroku alternatives are real products with genuine use cases. They are not the right answer for every team, and the evaluation should be made with the full cost picture visible, not just the infrastructure bill.
The TCO analysis for a self-hosted Heroku alternative has four components: infrastructure (cheap), initial setup engineering (significant upfront), ongoing maintenance engineering (continuous and compounding), and on-call burden (invisible in budgets, visible in retention). When all four are included, the self-hosted path is cheaper than a managed IDP only when a dedicated platform engineer’s time is already fully allocated to infrastructure work and not competing with product development.
The long-term architectural risk of the self-hosted path is the scale ceiling, the expertise dependency, and the platform drift, three risk categories that compound silently over two to three years and surface as a re-platforming project at the moment of least available engineering capacity.
The long-term architectural risk of the managed PaaS path is the infrastructure opacity, the compliance ceiling, and the vendor dependency on a provider whose infrastructure the team does not own, risks that surface specifically when enterprise customers arrive, and the security questionnaire requires answers the platform cannot support.
The cloud-native IDP path on the team’s own AWS account resolves both risk profiles: the platform is managed (no maintenance burden), but the infrastructure is owned (compliance posture, vendor independence, no scale ceiling). The engineering hours that a self-hosted alternative would consume return to the product roadmap. The compliance posture that a managed PaaS cannot provide is native to the AWS environment from day one.
Get Started with LocalOps → First production environment on AWS in under 30 minutes. No credit card required.
Schedule a Migration Call → Our engineers walk through your specific stack, whether you’re currently on Coolify, Dokku, or Heroku, and map the migration path to AWS.
Read the Heroku Migration Guide → Full technical walkthrough: database migration, environment setup, CI/CD pipeline configuration, DNS cutover.