
What Is AI SRE? A Guide to AI-Powered Incident Response and Root Cause Analysis (2026)
How AI SRE differs from AIOps, the four capabilities that define it, and whether it's safe to run in production



An AI SRE is a software agent that performs the investigative work of a site reliability engineer during a production incident. It queries logs, metrics, traces, and recent deploys, forms a hypothesis about the cause, tests it against the available data, and proposes a remediation. A monitoring tool reports that a threshold was breached. An AI SRE attempts to explain why it was breached and returns a ranked root cause rather than a raw alert.
The distinction is between detection and investigation. Detection is largely solved. A p95 latency alert fires within seconds of the threshold trip. The time cost sits after that: correlating the alert against logs, dashboards, and the last deploy to determine what actually changed. On most teams that step takes 20 to 40 minutes of manual work across four or five tools. An AI SRE targets that step specifically.
AI SRE is the sharp end of a broader shift toward AI for DevOps, where agents take on operational work that used to be fully manual. This post covers what an AI SRE is, how it differs from AIOps and from a human SRE, the telemetry it reasons over, and the question most vendor pages skip: whether it is safe to give one write access to production.
TL;DR
AI SRE vs AIOps. AIOps is the older, narrower discipline: machine learning that correlates alerts and reduces noise. It groups symptoms. An AI SRE investigates the system and proposes a cause.
It does not replace human SREs. It removes first-pass investigation and routine remediation. SLO design, novel failures, and production changes still need human judgment.
Autonomous remediation is narrow and governed. Auto-execution is becoming normal for known failure classes (OOM kills, pod evictions, connection pool exhaustion) run through pre-approved runbooks. General-purpose autonomy stays rare, limited by trust, topology accuracy, and governance rather than model capability.
Past a baseline reasoning level, context completeness drives output quality more than model size. An agent grounded in live topology, recent deploys, and service ownership does not have to reconstruct those facts mid-incident, and that reconstruction step is where wrong causal links creep in.
What is an AI SRE? The agentic difference
The word carrying the definition is agent. A monitoring tool runs a fixed query and fires when a threshold trips. An AI SRE does not follow a fixed path. It chooses what to inspect next based on what it just found.
The loop: p95 latency spikes, so it pulls the breakdown by endpoint, sees checkout is the outlier, checks what deployed near that timestamp, finds a payments-api release twelve minutes prior, reads the diff, and lands on a slow database query. Look, hypothesize, test, narrow. That loop is what separates it from the dashboards and pagers already in place.
It is not a chat box bolted onto one dashboard. A summarizer sees only the tool it lives in. An AI SRE works across telemetry sources and change history at once, which is where on-call wastes the most time: jumping between tools to assemble a timeline.
Correlating anomalies across services predates LLMs. Reading a diff, a log line, and a deploy timestamp together, and explaining why they’re connected, is what’s new — and it’s the part that shortens an incident.
AI SRE vs AIOps: what’s the actual difference?
AIOps and AI SRE solve different parts of the incident problem. AIOps correlates alerts and cuts noise. An AI SRE investigates the system and proposes a root cause. One operates on the alerts. The other operates on the evidence underneath them.
AIOps is the older term. Gartner coined it around 2016 for machine learning applied to IT operations data: anomaly detection, event correlation, noise reduction. Its job is to take a flood of alerts and group the related ones into fewer, deduplicated incidents. That is useful. It is also limited. Correlating alerts is not the same as diagnosing a cause. If a thousand alerts collapse into fifty groups, the result is fifty groups, not an answer about which one is breaking checkout.
An AI SRE works one layer down. It does not stop at the alert stream. It queries the actual system state: logs, metrics, traces, and the deploy history. It runs the look-hypothesize-test loop until it has a ranked cause. AIOps tells you these alerts are related. An AI SRE tells you the payments-api deploy twelve minutes ago is the likely reason.
The market formalized this split recently. Gartner published its first Market Guide for AI Site Reliability Engineering Tooling on January 26, 2026, separate from its older AIOps coverage, and projected enterprise adoption rising to 85% by 2029 from under 5% at publication.
The two are not competitors. Noise reduction makes an AI SRE’s job easier by lowering the alert volume it reasons over. Most mature setups run both: AIOps thinning the stream, the agent investigating what survives.
What can an AI SRE actually do? The four core capabilities
To automate incident response end to end, an AI SRE has to do four distinct things and the chain is only as strong as its weakest link. Most tools marketed as “AI SRE” do the first one well and overstate the third.
Triage and correlation. Reads every incoming alert, suppresses duplicates and known-noisy ones, groups related alerts into a single incident, and scores severity. This is the part that overlaps with AIOps. Its job is to stop a human getting paged for the alerts that do not matter.
Investigation and root cause analysis. This is the capability that defines the category. The agent queries logs, metrics, traces, and recent change events, forms hypotheses, tests them against the data, and returns a ranked cause with confidence. Investigation is the slowest part of incident response, so this is where the time is won.
Remediation. Proposes a fix and, for well-understood failures, executes it through a pre-approved runbook. Rollback, restart, scale, drain. This is the most over-marketed capability and the one that carries the most risk, which is why it sits behind approval.
Memory. Stores past incidents with their causes and fixes, and surfaces look-alikes on new alerts. The second occurrence of a pattern resolves faster than the first.
is gated. The reasoning step is the part that is hard to build and the part that decides whether the tool is worth running.
How does an AI SRE work?
An AI SRE works by reasoning over telemetry the same way an on-call engineer does, except it runs the queries in parallel and does not get tired at 3am. The mechanics come down to two things: the signals it can see, and the loop it runs over them.
It reasons over four signal types:
Logs — what the services wrote. Loki is a common source.
Metrics — latency, error rate, saturation. Usually Prometheus, viewed in Grafana.
Traces — the path of a request across services, fed by OpenTelemetry instrumentation.
Change events — deploys, config changes, feature flag flips, scaling actions. This is the one teams forget, and the one that matters most.
A large share of production incidents trace back to a recent change, which is why the deploy history is so often where the answer is. DORA tracks this directly through its change failure rate metric, covered in the next section. An agent that cannot see what shipped twelve minutes ago is investigating with one eye closed. The agent reads from these sources. It does not replace them.
The investigation itself is a loop, not a single pass. The agent looks, forms a hypothesis, tests it against the data, narrows, and repeats until it has a cause it can rank with confidence. Here is that loop on a real-shaped incident: a checkout p95 > 2s alert.
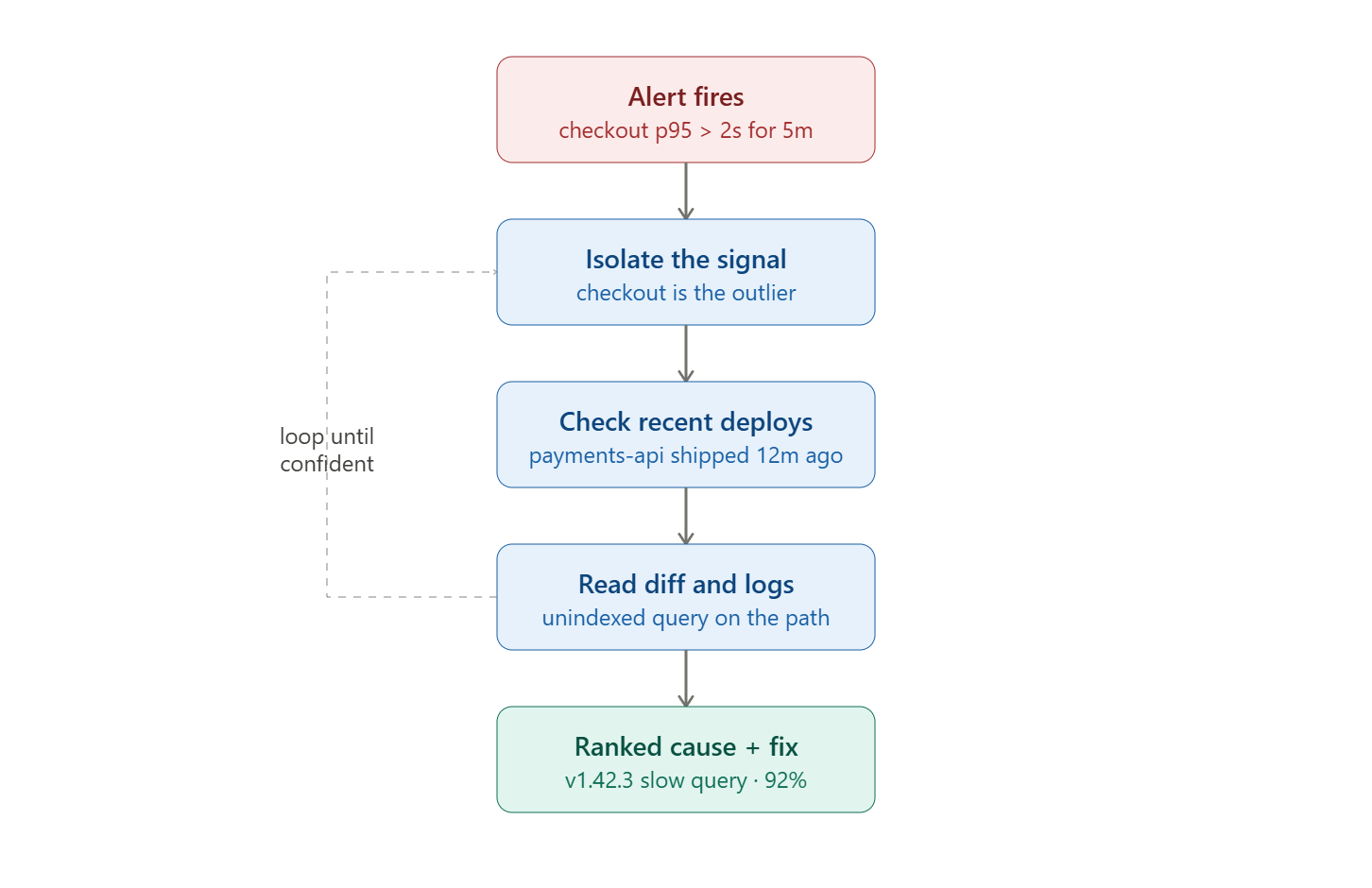
Manual triage on an incident like this typically runs 20 to 40 minutes, much of it spent moving between separate tools to assemble a timeline. An agent compresses that to about the length of a single investigation pass, for two reasons:
It runs the queries concurrently, not one tool at a time.
It already knows the topology, so it does not stop to ask what payments-api is or what it depends on.
That second reason is the whole argument:
An agent with context starts investigating immediately.
An agent without it spends its first several steps reconstructing basic facts, and reconstruction is exactly where wrong causal links get introduced.
Past a baseline reasoning level, root cause analysis quality is decided by context completeness, not model size.
This is why a platform that already maintains a live service catalog and deploy history, the kind an internal developer platform like LocalOps keeps by default, gives an agent better ground to reason from than a model bolted onto telemetry it has to map from scratch.
Reactive incident response vs proactive detection: what changes?
Reactive incident response means a human waits for a threshold to trip, gets paged, and starts investigating. Proactive detection means the system correlates signals and surfaces a likely problem before it crosses into a customer-facing outage. The difference is where the work starts: after the page, or before it.
Traditional monitoring is reactive by design. A metric crosses a static threshold and an alert fires. The problem is volume:
Industry data puts the false-positive rate around 85%, with roughly two-thirds of alerts going uninvestigated.
When most pages are noise, the real one gets missed inside it.
The Google SRE Workbook sets a benchmark for sustainable on-call: a maximum of two genuinely actionable incidents per shift, to leave time for follow-up. By that standard:
A team consistently paged eight or ten times a shift is not overloaded on-call. It has an alerting problem.
Adding more reactive thresholds makes it worse, not better.
Proactive detection changes the order of operations:
It correlates across signals instead of firing on one metric in isolation.
It weighs an alert against recent deploys and known past incidents before deciding it matters.
It can flag a slow degradation, like an error rate creeping from 0.06% to 0.18%, before it breaches a hard threshold.
The standard reliability metrics live here, and two get conflated constantly:
MTTD (mean time to detect): how long from failure to the system noticing.
MTTR: the slippery one. It stands for time to detect, acknowledge, restore, or repair depending on who is talking, and conflating them is how teams lie to themselves about reliability.
DORA tracks failed-deployment recovery time and change failure rate as two of its core metrics, because how fast you recover and how often a change breaks production are better reliability signals than raw alert counts.
MTTR reduction is the metric most teams actually buy an AI SRE for, and an it moves both:
Faster detection, through correlation rather than static thresholds.
Faster recovery, through ranked root cause instead of manual log digging.
Is it safe to give an AI SRE access to production?
It is safe if the access is scoped correctly. The risk is not that an agent investigates production. Reading logs and metrics is low-stakes. The risk is an agent changing production on its own. The line that matters is between read and write.
A well-designed AI SRE separates the two with a few concrete controls:
Read-only by default. The agent investigates with read-only credentials. It can see everything and change nothing. Write access is a separate, narrower grant.
Scoped, least-privilege IAM. The agent acts only within a defined blast radius. Even an approved action cannot reach beyond what its role permits, so a bad call stays contained.
Approval in the tools you already use. A proposed fix appears in Slack or Teams, and a human approves before it runs. No console-diving at 2am to authorize.
Audit trail on every action. Each investigation step and every executed change is logged. This is the first thing a security or compliance reviewer asks for.
There is one more control that matters more than the rest: the agent has to show its reasoning, not just its conclusion. An approve button on a black-box recommendation is not oversight. It is rubber-stamping. The value is the agent surfacing why it thinks v1.42.3 is the cause, with the evidence attached, so a human can actually judge the call. This is the human-oversight principle in NIST’s AI Risk Management Framework and the EU AI Act, applied to operations.
The reason full autonomy stays gated is asymmetric cost:
A missed suggestion costs a few minutes.
A wrong autonomous action during a partial outage can turn a P2 into a P1.
Until an agent’s judgment is provably better than a tired human’s on novel incidents, not just familiar ones, the human stays in the loop. That is why the 2026 state is bounded autonomy: auto-execution for a narrow set of known failure classes through pre-approved runbooks, with everything else escalated.
This is the honest ceiling for automated incident management today: a lot of the response automated, the riskiest decisions still gated by a human.
There is a second safety question that has nothing to do with remediation: where does your data go? Logs and metrics often contain regulated data, so an AI SRE that ships them to a third-party SaaS for inference is a data-residency decision, not just a technical one. The stricter architecture keeps inference inside your own cloud account:
The agent runs against telemetry in your VPC.
Raw logs and production data do not leave your perimeter.
You can verify this in your own egress logs, not just the vendor’s documentation.
This is the architecture behind LocalOps’s Lookout AI, currently in private beta. It installs into a Kubernetes cluster, connects to your existing Prometheus, Loki, and Grafana, and starts ranking alerts and proposing root causes against telemetry that stays in your own cloud rather than being pulled into a vendor’s.
When does a team actually need an AI SRE? (and when it doesn’t)
An AI SRE earns its place when the volume of incident work outgrows the people handling it. The clearest signals:
On-call is paged past the sustainable limit, and engineers are losing sleep to noise.
There is no dedicated SRE, and a founder or senior engineer is the de facto rotation.
Enterprise customers have SLAs, so slow recovery carries contractual and renewal risk.
Investigation, not detection, is where incidents stall.
It is the wrong tool, or premature, when:
Alert volume is genuinely low and a human handles it without strain.
The product is pre-fit and the system changes shape weekly, so there is little stable topology to reason over.
The expectation is hands-off autonomy. That is not what the technology does in 2026.
The honest framing for teams under 100 engineers: an AI SRE removes the toil of first-pass investigation and routine remediation. It does not remove the need for someone who owns reliability decisions. If you are choosing between an AI SRE and a first SRE hire, the answer is usually not either-or. It is an agent for daily operations plus fractional senior human time for the judgment calls.
FAQs
Is AI SRE the same as AIOps?
No. No. AIOps in DevOps refers to machine learning that correlates alerts and cuts noise; it groups related symptoms. An AI SRE works a layer down, investigating logs, metrics, and deploys to propose a root cause. Most mature setups run both.Can an AI SRE resolve incidents on its own?
Only within limits. It can auto-execute fixes for a narrow set of known failures through pre-approved runbooks. Everything else stops at a proposed action a human approves, because a wrong automated change costs far more than a missed suggestion.Will an AI SRE replace human SREs?
No. It removes first-pass investigation and routine remediation. It does not design SLOs or handle failures with no precedent. The common pattern is an agent for daily operations plus senior human time for the decisions that matter.Does an AI SRE send my production data to a third party?
It depends on the architecture, so check before you buy. Logs often contain regulated data. The stricter model keeps inference inside your own cloud account, so raw logs never leave your perimeter.Do I need an existing monitoring stack to use an AI SRE?
Yes. An AI SRE reasons over telemetry, so it needs logs and metrics underneath it. It reads from your observability stack rather than replacing it; without one, you need that signal in place first.
What to Look for in an AI SRE?
There is a fact from 2026 that should sit underneath every AI SRE purchase decision: operational toil went up last year, not down, even as AI spending climbed. The reading that matters is not that the tools failed. It is that most of them were bolted onto stacks they did not understand, asked to reason about systems they had to reconstruct from scratch.
That is the whole lesson. An AI SRE is not magic and it is not a headcount replacement. It is an investigation engine, and an investigation engine is only as good as the context it starts with. Give it a live picture of your services, your deploys, and your topology, scope its access so it can read freely and change carefully, and it removes the part of on-call that no one should be doing at 2am. Give it raw telemetry and no context and you get confident wrong answers faster.
So the question to ask is not how clever the model is. It is what the agent already knows about your system before the incident starts, and where your data goes when it does. That is the bet LocalOps is making with Lookout AI: an on-call agent that runs inside your own cloud, on context the platform already holds.
Lookout AI is in private beta. It installs into your cluster, reads from your existing Prometheus, Loki, and Grafana, and starts ranking alerts and proposing root causes without your telemetry leaving your account.
Full Disclosure, I build in this space too, operatex.dev,
so take this as a peer note not a sales pitch. Fully agree on the read versus write line, that's the one distinction that actually matters and most vendor pages miss it on purpose. The context completeness point is undervalued too, an agent that has to rediscover your topology every incident is doing half its work over again before it even starts investigating.